
I have a bunch of these myself and that is my experience, but don’t have any screenshots now.
However there’s great comparison of these thin clients if you don’t mind Polish: https://www.youtube.com/watch?v=DLRplLPdd3Q
Just the relevant screens to save you some time:
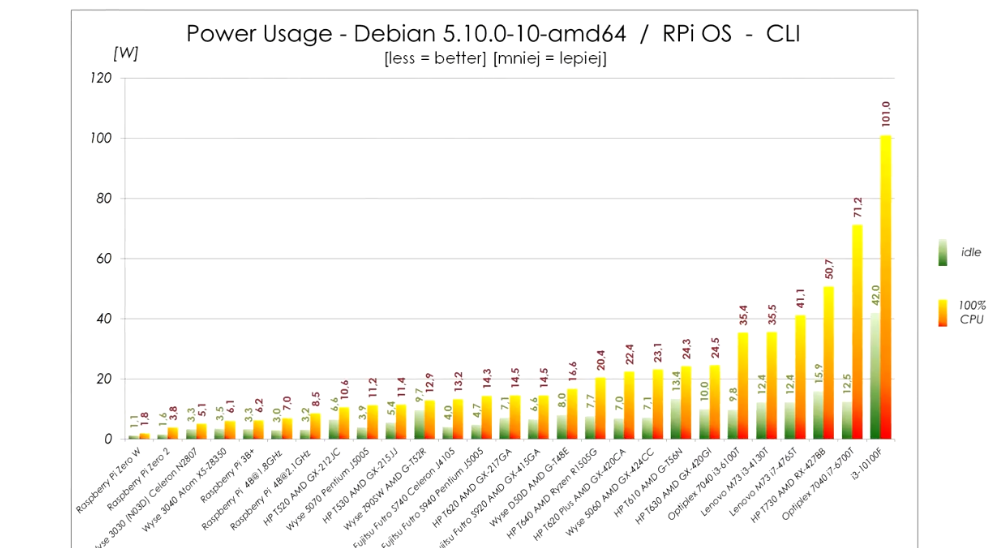
Power usage:
Cinebench multi core:
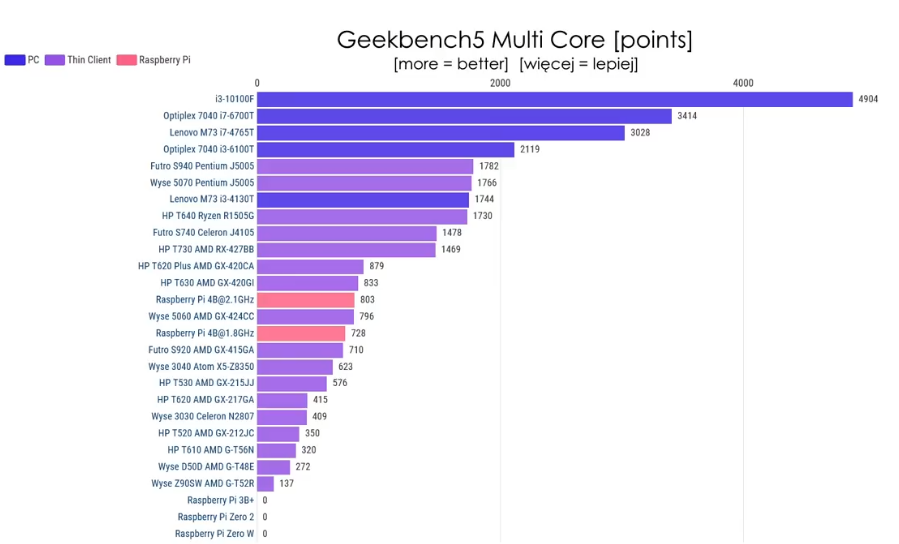
The power usage in idle is within 2W from Pi 4 and the performance is about double compared to overclocked Pi 4. It’s really quite viable alternative unless you need really small device. The only alternative size-wise is slightly bigger WYSE 3040, but that one has x5-z8350 CPU, which sits somewhere between Pi3B+ and Pi4 performance-wise. It is also very low power though and if you don’t need that much CPU it is also very viable replacement. (these can be easily bought for about €60 on eBay, or cheaper if you shop around)
Also each W of extra idle power is about 9kWh extra consumed. Even if you paid 50c/kWh (which would be more than I’ve ever seen) that’s €5 per year extra. So I wouldn’t lose my sleep over 2W more or less. Prices here are high, 9kWh/y is rounding error.
I’m curious. How would you identify who’s guest and who’s not in this case?
With multiple networks it’s pretty easy as they are on a different network.